Last Updated on 1 month ago by Bernard Mugo
Qualitative coding mistakes are more common than most PhD students realize — and some of them are quietly ruining otherwise solid research. In this guide, I’ll walk you through 12 of the most damaging errors researchers make when coding qualitative data, and show you exactly what to do instead.
- What Is Qualitative Coding? (And Why Getting It Right Matters)
- Mistake 1 – Using Too Large a Sample
- Mistake 2 – Skipping Data Familiarization
- Mistake 3 – Inconsistent Transcript Naming
- Mistake 4 – Not Classifying Documents into Coding Groups
- Mistake 5 – Coding Without Your Research Question in View
- Mistake 6 – Coding Too Little of Each Passage
- Mistake 7 – Ignoring Inconvenient Results
- Mistake 8 – Inconsistent Coding
- Mistake 9 – Overcoding and Undercoding
- Mistake 10 – Letting Researcher Bias Take Over
- Mistake 11 – Lack of Transparency in Your Coding Process
- Mistake 12 – Being Too Rigid in Your Approach
- Frequently Asked Questions
- Key Takeaways
- Need Help with Your Qualitative Analysis?
What Is Qualitative Coding? (And Why Getting It Right Matters)
Qualitative coding is the process of reading through your interview transcripts, focus group notes, or other qualitative data and attaching short, interpretive labels — called codes — to passages that are meaningful to your research question. It is the foundation of most qualitative analysis methods, including thematic analysis.
Coding always comes before theming. You generate codes first, then look for patterns of shared meaning across those codes to develop themes. If you want to see what that full process looks like in practice, my guide on thematic analysis examples: inductive and deductive walks through it step by step.
The mistakes below apply whether you’re coding manually in Word or using specialist software like NVivo, MAXQDA, or ATLAS.ti. Getting these right is what separates credible, publishable findings from a weak analysis that reviewers will pick apart.
Mistake 1 – Using Too Large a Sample
If you’re a PhD student, choosing the right sample size is critical. Many beginners assume bigger is better and interview far more participants than necessary. But coding and analysing large samples takes enormous time and effort — and often adds no analytical value.
Instead, rely on data saturation — the point at which new interviews stop bringing new insights. Scribbr’s guide to qualitative research methods explains data saturation clearly: if 15 participants get you there, interviewing 30 won’t add anything meaningful. Focus on quality over quantity.

Mistake 2 – Skipping Data Familiarization
One of the most damaging mistakes you can make is jumping straight into coding without first spending time getting familiar with your transcripts. After transcription, read through at least half of your data like you’re reading a story — before you assign a single code.
This step helps you understand the depth and nuance in participants’ responses, spot patterns early, and make your eventual coding more accurate and insightful. If you have 8 transcripts, read at least 5 thoroughly first. Take short notes on anything that surprises you.
Mistake 3 – Inconsistent Transcript Naming
Failing to standardise how you name your participants is a rookie mistake with real consequences. Files labelled “Recording 5” or inconsistent pseudonyms can accidentally reveal someone’s identity and make your analysis confusing to follow.
Develop a clear naming system before you start coding — “Participant 1,” “Participant 2,” or pseudonyms like “Jane” and “Mark.” Tools like NVivo, MAXQDA, and ATLAS.ti all have built-in functions to assign and manage these pseudonyms. My step-by-step guide on qualitative coding in NVivo shows exactly how to set this up.
Mistake 4 – Not Classifying Documents into Coding Groups
If you’re using NVivo, MAXQDA, or ATLAS.ti and you skip organizing your documents into the right groups, you’re limiting your analysis from the start. Say you’ve interviewed doctors, nurses, and patients. Without grouping them properly, you lose the ability to compare perspectives across roles — often the most insightful part of the analysis.
Before you start coding, classify your documents based on participant type, demographics, or other relevant variables. Use the folders, cases, sets, or attributes functions in your QDA software. This small step makes your findings richer and more credible.
Mistake 5 – Coding Without Your Research Question in View

When you forget what you’re coding for, you start tagging anything and everything. Your coding turns into aimless note-taking instead of focused analysis — and you end up with cluttered data, diluted themes, and a pile of irrelevant codes.
Fix: keep your research questions and objectives physically in view while you code. A sticky note, a printed prompt, a sticky tab on your screen — whatever it takes. Ask yourself at every passage: “Does this help answer my research question?” Coding is a process of elimination, not inclusion.
Mistake 6 – Coding Too Little of Each Passage
Some researchers highlight a single word or vague phrase and assign a code to it. The problem is that there’s not enough context for anyone — including your future self — to understand why you coded it that way. A one-word quote cannot carry the weight of a full idea.
Include enough surrounding text to clearly show why the code applies. But don’t over-extract either — a sentence or two is usually enough. Think of it like quoting in an essay: enough to make your point, not so much that the reader gets lost.
Mistake 7 – Ignoring Inconvenient Results
Some researchers go into analysis already knowing what they want to find. When the data doesn’t align, they cherry-pick, twist interpretations, or ignore what participants actually said. That’s not research — it’s confirmation bias, and it directly undermines your credibility.
If your findings contradict your expectations, that’s not failure — it’s valuable insight. Stay objective and transparent. Highlight your original assumptions, then honestly explain how the data led you somewhere different. This openness doesn’t weaken your study; it makes it stronger.
Mistake 8 – Inconsistent Coding
Inconsistent coding happens when you apply different logic to similar data segments — coding a quote as “work stress” one day and an almost identical quote as “burnout” the next, with no explanation. The result is messy data, weak themes, and shaky findings.
To avoid it: write clear definitions for each code and stick to them. Review your coding decisions regularly. If working with others, run inter-coder reliability checks to make sure everyone is applying the same criteria.
Mistake 9 – Overcoding and Undercoding
Overcoding means tagging a single quote with every code under the sun — your data becomes a cluttered mess and the main point disappears. Undercoding is the opposite: you barely tag anything, and rich, nuanced quotes get one generic label and nothing more.
The fix is balance. Use a layered or hierarchical code structure — broad themes at the top, with more specific sub-codes underneath. Saldaña’s Coding Manual for Qualitative Researchers is the gold standard reference for understanding how to build this kind of structure without losing clarity.
Mistake 10 – Letting Researcher Bias Take Over
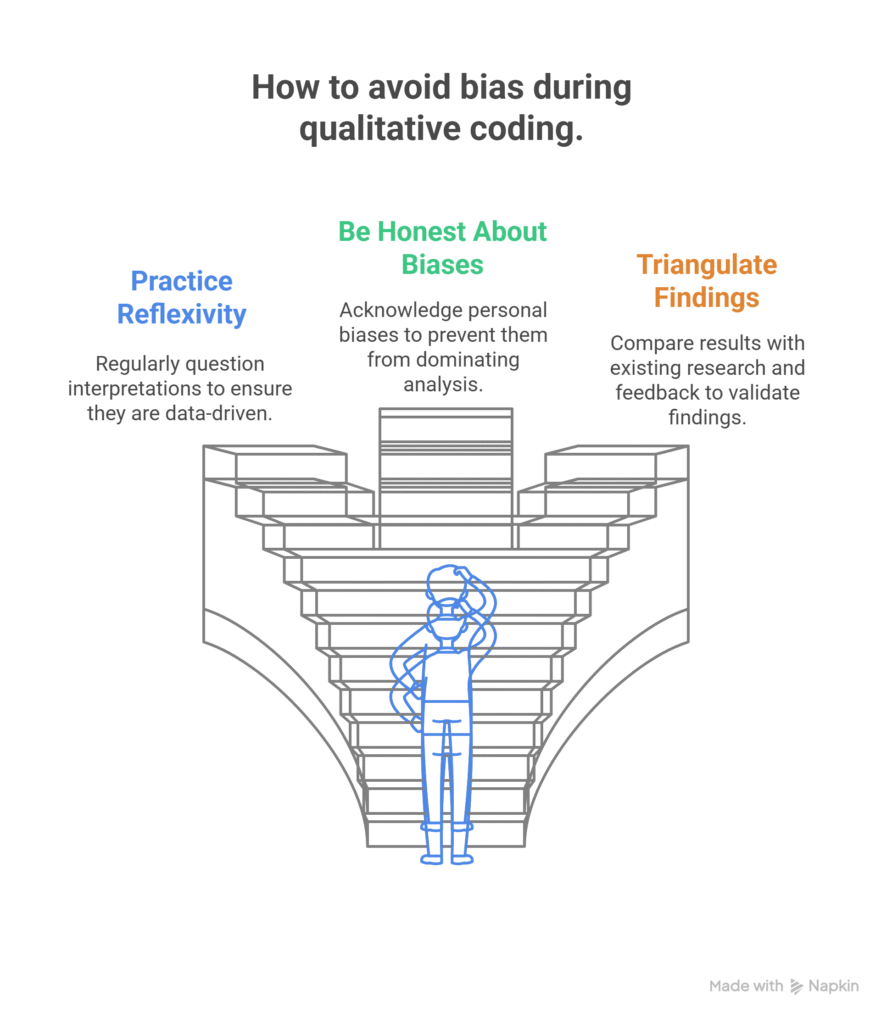
Coding with bias means walking into your data already knowing what you want to find — then bending codes to fit your assumptions instead of listening to what participants actually said. That’s not analysis; it’s confirmation.
Avoid it through reflexivity: regularly ask yourself, “Am I interpreting this based on the data or my own lens?” Write a reflexivity section in your methodology — usually titled the researcher’s role. Triangulate your findings against existing research or peer feedback. My guide on reflexive thematic analysis in NVivo covers how to do this systematically.
Mistake 11 – Lack of Transparency in Your Coding Process
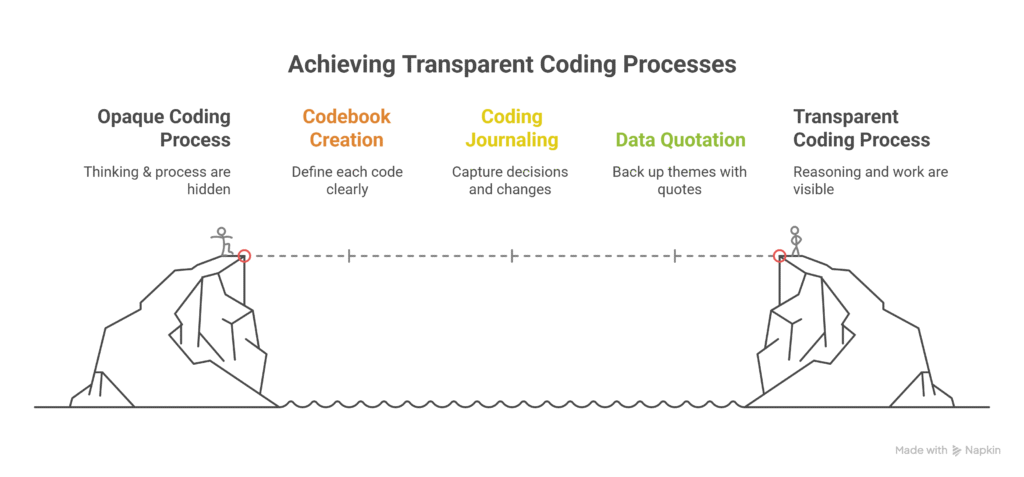
If someone looked at your analysis, could they follow your thinking? Many researchers assign codes, build themes, and reach conclusions — but leave no trail. That’s a credibility problem, and in a dissertation or peer-reviewed paper, it’s a red flag for reviewers.
Stay transparent by keeping a codebook that defines each code clearly, using coding memos to capture decisions and changes along the way, and always including direct quotes from your data to support your themes. Don’t just summarise — show your reasoning.
Mistake 12 – Being Too Rigid in Your Approach
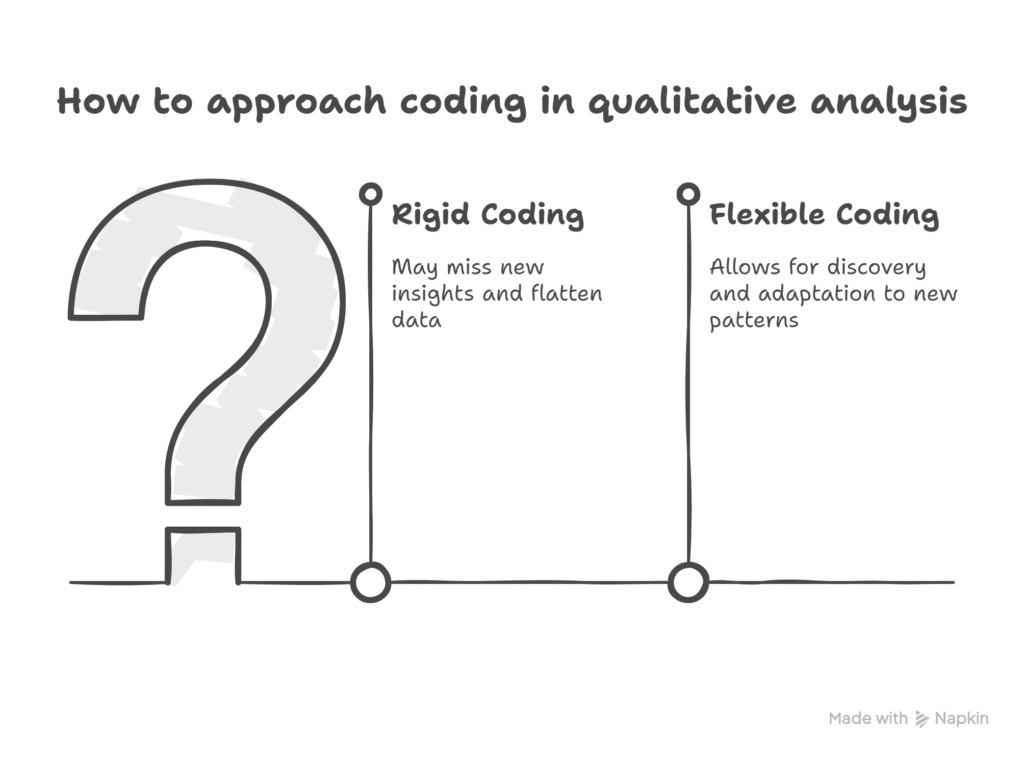
Coding is not a rigid checklist you run once and never revise. If you force every data segment into a fixed set of codes from the start, you miss the point of qualitative analysis: discovery. When you don’t adjust as new insights emerge, you risk flattening your data.
Choose a coding approach that fits your research question — not someone else’s template. Stay open: expect your categories to shift, evolve, and deepen as you work through your data. Revisiting and revising earlier coding is not a failure; it’s part of the process. For a practical example of this in action, see my guide on qualitative coding in Microsoft Word where I demonstrate iterative coding from scratch.
Frequently Asked Questions
What is the most common qualitative coding mistake? The most common is coding without keeping research questions in view, which leads to unfocused, bloated code lists that don’t map to any meaningful themes.
How do I know if I’m overcoding or undercoding? Overcoding feels like every line has three or more codes attached. Undercoding feels like you’ve only tagged a handful of passages across a long transcript. If in doubt, aim for one or two codes per meaningful passage, and build sub-codes rather than stacking multiple codes on the same excerpt.
Do I need specialist software to avoid these mistakes? No — these mistakes happen in manual coding too. But tools like NVivo and MAXQDA make it much easier to stay organised, maintain consistency, and keep a clear coding trail. If you’re working with more than 5 transcripts, software is strongly recommended.
What is data saturation? Data saturation is the point in qualitative research where new interviews stop producing new insights. It’s the main criterion for determining an adequate sample size in inductive qualitative research.
How do I improve consistency across coders? Write a codebook with a clear definition and example for every code before coding begins. Run a pilot round where all coders code the same transcript, then compare and reconcile differences. This is called inter-coder reliability checking.
Key Takeaways
- Always keep your research questions in front of you while coding — coding is focused, not exhaustive
- Read at least half your transcripts before you assign a single code
- Standardise participant naming before you start to protect confidentiality and keep your analysis clean
- Use a layered code structure to avoid both overcoding and undercoding
- Maintain a codebook and coding memos so your reasoning is transparent and auditable
- Stay flexible — expect your codes and categories to evolve as you work through the data
Need Help with Your Qualitative Analysis?
If you’re working through your qualitative analysis and want expert support, I offer a done-for-you qualitative analysis service covering NVivo, MAXQDA, and ATLAS.ti — from your raw transcripts to a complete findings report. You can also book a one-to-one consulting session to work through your coding together. Reach out at bernardmugo@survivingresearch.com — I’m happy to help.

