Last Updated on 1 month ago by Grace Nyambura
If your qualitative analysis is biased, your entire research is at risk — and the scariest part is that most researchers don’t realise the bias is there. In this guide, I’ll show you exactly how to do blind coding in NVivo so your findings are more objective, more consistent, and far more defensible when you get to your viva or defence.
| What is blind coding? Blind coding is a qualitative analysis technique where you code your data without knowing who provided it. Instead of seeing “Interviewee 1, female manager, 45 years old,” you only see “Participant A.” This removes a major source of unconscious bias from your analysis. |
What Is Blind Coding in Qualitative Research?
Blind coding is the process of analyzing qualitative data without knowing the identity of the participant.

Instead of seeing:
- Interviewee 1 – Female, Blind coding means you code your data without knowing who said it or who provided it. The moment you know the identity of a participant — their gender, seniority, age, or background — your brain starts making assumptions. That is exactly how bias creeps into your analysis, usually without you noticing.
- A simple example: if you know that Interviewee 3 is the most senior manager in your dataset, you may unconsciously assign more weight to her responses, or interpret an ambiguous comment as more authoritative than it is. Blind coding removes that risk by replacing all identifying information with neutral labels like Participant A, Participant B, and so on.
- For a broader overview of why qualitative research requires these safeguards, Scribbr’s guide to qualitative research methods is a useful starting point

Why Blind Coding Matters for Your Research
There are three core reasons to build blind coding into your NVivo workflow.
1. It Reduces Bias
When you can’t see who said something, you’re forced to code based on what was said — not your assumptions about the person saying it. You are not influenced by gender, role, seniority, age, or any other characteristic that could skew your interpretation.
2. It Improves Coding Consistency
Blind coding pushes you to apply the same logic across all participants. You’re not unconsciously treating a manager’s response differently from a junior employee’s. Your codes become more consistent, which directly improves the reliability of your analysis.
3. It Strengthens Your Findings
Examiners and peer reviewers look for evidence that your findings are trustworthy. Blind coding is one of the clearest signals you can provide that you took steps to manage researcher bias. According to Braun and Clarke’s foundational thematic analysis framework, reflexivity and rigour in the coding process are central to credible qualitative findings. Blind coding is one of the most practical ways to demonstrate both.
How to Do Blind Coding in NVivo: 5 Steps
Here is the exact process I walk my clients through when setting up blind coding in NVivo.
Step 1 — Remove All Participant Identifiers Before Importing
Before you open NVivo, go into your transcripts and replace every participant’s name with a neutral label — Participant A, Participant B, Participant C. Remove anything that could reveal identity: job titles, gender references, specific locations, and any personal details.
The goal is simple: by the time you open your transcript in NVivo, you should genuinely not be able to tell who said what. This step happens in Word or wherever your transcripts live — not inside NVivo itself.
Step 2 — Import Your Clean Transcripts Into NVivo
Once your transcripts are anonymised, open NVivo and import them as sources, treat each transcript as a separate source file. At this point your data is clean, your participants are labelled neutrally, and you’re ready to begin blind coding. If you want a walk-through of the import process, my post on qualitative coding of interviews with NVivo covers this in detail.
Step 3 — Code for Meaning, Not for Who Said It
As you read through each transcript, focus entirely on what is being said, not who is saying it. Actively resist any temptation to interpret meaning through the lens of participant identity.
For example: instead of reading a comment about resource constraints and thinking “that sounds like a frustrated manager,” code what the comment is actually about — leadership challenges, resource allocation, team pressure. The code should describe the content, not your assumption about the speaker.
Step 4 — Use a Consistent Coding Framework Throughout
Create clear definitions for each of your codes before you start, and stick to them. If you coded a particular issue one way in Participant A’s transcript, code the same issue the same way in Participant D’s transcript. Don’t let your definitions shift halfway through.
NVivo’s memo feature is useful here — write brief definitions for each code as you create it. NVivo’s official documentation has guidance on setting up and managing code definitions within the platform.
Step 5 — Review Your Codes for Consistency After Initial Coding
After you complete your initial pass through all transcripts, go back and review your coding for consistency before moving on to the next phase of analysis.
If you’re using the Braun and Clarke six-step thematic analysis framework, this review happens after Step 2 (generating initial codes) and before Step 3 (searching for themes). My post on inductive thematic analysis using NVivo walks through the full process step by step.
Pro Tips to Take Your Blind Coding Further
Combine Blind Coding With Inter-Coder Reliability
Inter-coder reliability means having a second independent person code your data separately, then comparing your codes and agreeing on a final coding scheme. This person could be a fellow PhD student or a colleague with knowledge of your field.
When you combine blind coding with inter-coder reliability, you’re building two layers of protection against bias. Both coders work without knowing participant identities, then reconcile their codes. The resulting inter-coder agreement is a powerful indicator of reliability that examiners respond well to.
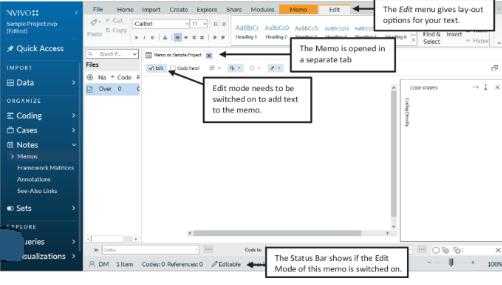
Use Memos to Track Your Coding Decisions
NVivo’s memo feature is one of the most underused tools in qualitative analysis. As you code, write short notes on why you chose a particular code — the reasoning, the context, any edge cases. This is especially important if you’re doing reflexive thematic analysis. SAGE Research Methods has an excellent overview of how memos function in qualitative research.
Only Reveal Participant Details After Coding Is Complete
Once your coding is fully complete, you can go back to your demographics table and integrate participant details into your analysis. At that point you might look at patterns by gender, role, or seniority — but only after the coding itself is done. This is how you keep your analysis clean and defensible.
Frequently Asked Questions
Does blind coding work for all types of qualitative research?
Blind coding is most useful in research where participant characteristics could introduce bias — interview studies, focus groups, and observational data. It’s less relevant for document analysis where the source is already obscured. When in doubt, apply it. The overhead is low and the benefit to your credibility is real.
What if my design requires knowing participant context during coding?
Some approaches — particularly interpretive phenomenological analysis or narrative inquiry — require you to hold participant context in mind as you code. In these cases, full blind coding may not be appropriate, but you can still practise partial anonymisation and document your reasoning carefully in memos.
Can I do blind coding in NVivo without changing my transcripts first?
No. The anonymisation must happen before you import. NVivo doesn’t have a built-in feature to hide participant metadata during coding. The transcript files themselves need to be clean before you bring them into the project.
Is blind coding the same as double coding?
No. Blind coding is about removing participant identity from your view during coding. Double coding (or inter-coder reliability) is about having two people code the same data independently. They address different threats to reliability and work best when used together.
Key Takeaways
- Remove all participant identifiers from your transcripts before importing into NVivo.
- Code for meaning and content — not for who you think said something.
- Use a consistent coding framework with written definitions for every code.
- Review for consistency after initial coding, before moving into theme development.
- Combine blind coding with inter-coder reliability for the strongest validity argument.
Need Help With Your NVivo Analysis?
Are you overwhelmed by your qualitative data? I offer two specialized services for PhD students who need support with N-Vivo analysis. The first is my done-for-you qualitative data analysis service, where I handle the full coding, theme development, data visualization, and a findings report — including a walk-through recording of the entire analysis. The second is one-on-one N-Vivo consulting, where we work together on a video call via Zoom or Microsoft Teams, and I guide you through your analysis step by step.
Ready to continue? Read my post on qualitative coding of interviews with NVivo next.
![How to Conduct a Qualitative Research Interview [7 Steps]](https://survivingresearch.com/wp-content/uploads/2026/01/How-to-conduct-qualiataitve-interviews.jpg)
